What Sounds Do We Remember?
What Makes A Sound Stick in Our Brain?
When we form memories, not everything that we perceive is noticed; not everything that we notice is remembered. Humans are excellent at filtering and retaining only the most important parts of their experience -- what if our audio compression had the same ability?
Our goal is to understand what makes sound memorable. With this work, we hope to gain insight into the cognitive processes that drive auditory perception and predict the memorability of sounds in the world around us more accurately than ever before. Ultimately, these models will give us the ability to generate and manipulate the sounds that surround us to be more or less memorable.
We envision this research introducing new paradigms into the space of audio compression, attention-driven user interactions, and auditory AR, amongst others.
Step 1. A New Dataset
We know that loud, itermittent sounds will capture our attention; we also know that when you're at a crowded bar, you'll hear your name even if it's spoken quietly. These two examples point to the fact that both lower level features of the sound (loudness) and higher level features (associated with a concept you care about) factor into how we process sounds in our environment.
There aren't any high quality audio datasets that include the higher-level cognitive features we're interested in, so we decided to make our own -- the first-of-its-kind NAM400! It features 400 hand-selected, 5-second open-source samples. They were chosen to roughly fall into 1 of 3 categories -- “Natural” sounds, or sounds that are both familiar and immediately recognizable; “Ambiguous” sounds that are familiar but difficult to label; and “Morphed” sounds, or those that we synthetically modified to sound unusual. The spanning of 'conceptual ambiguitity' (how easy it is to identify the conceptual source of a sound) is the first way the NAM400 is different than any other dataset.
Lower Level Features
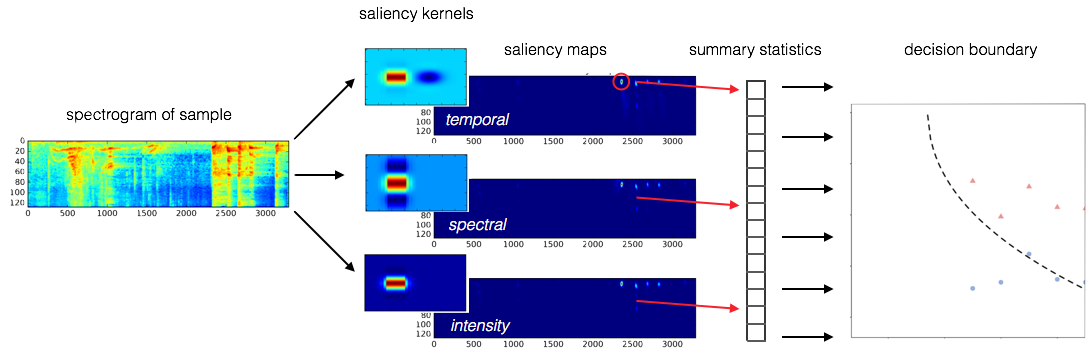
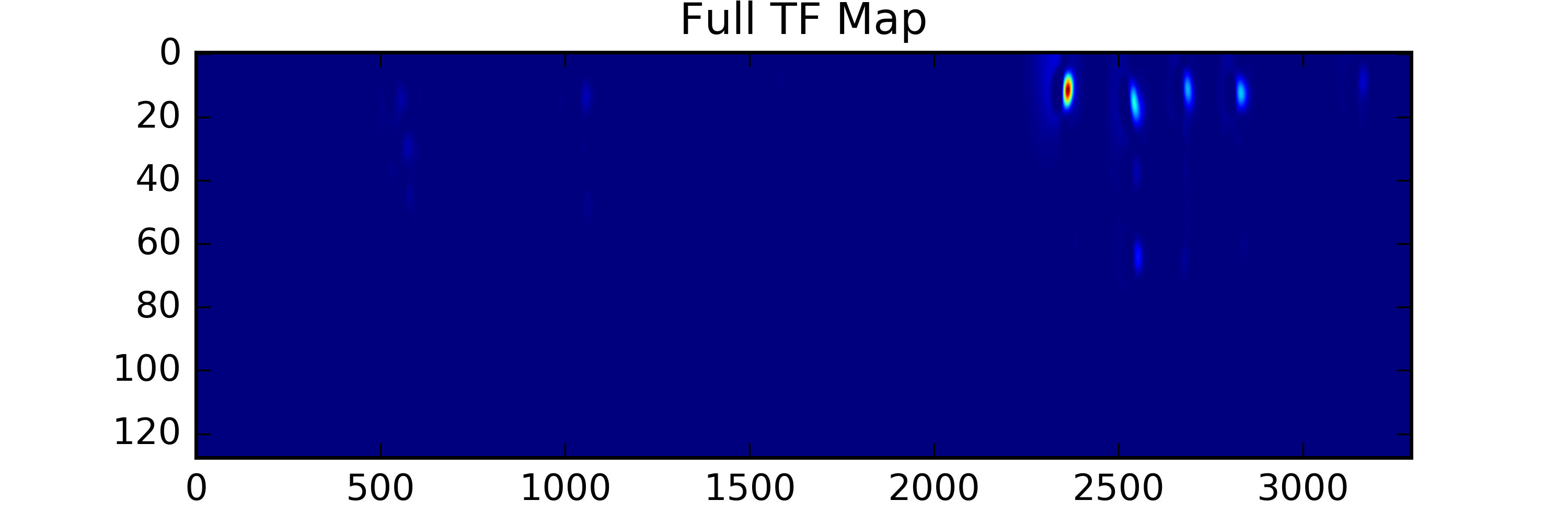
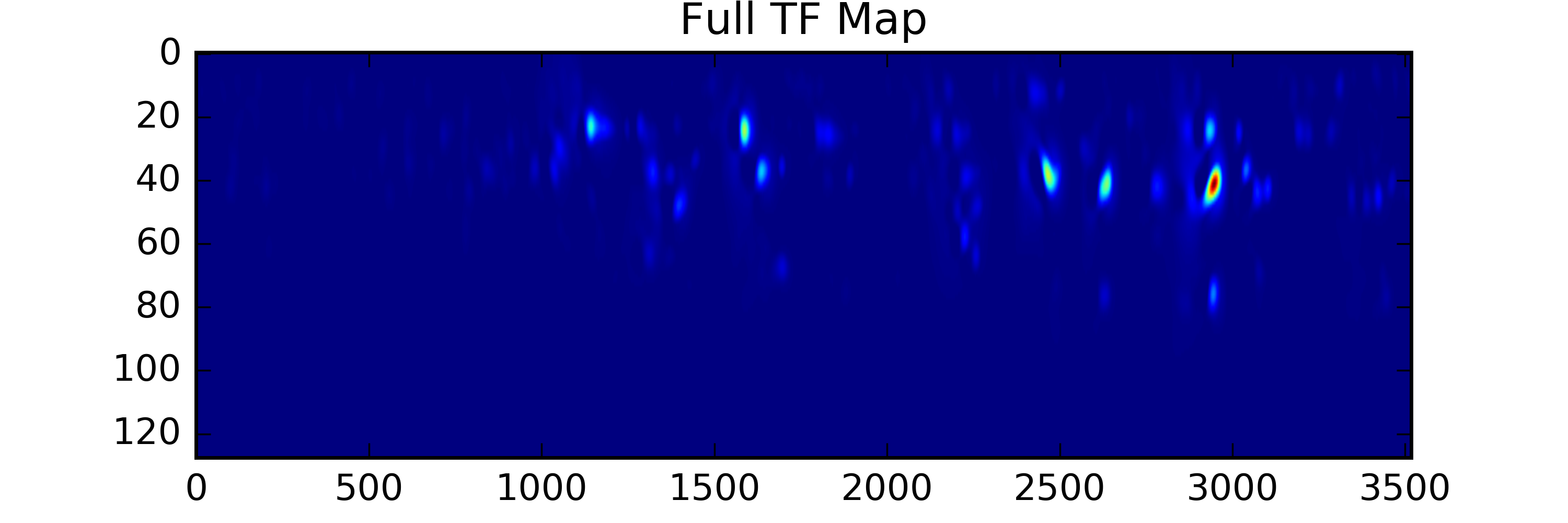
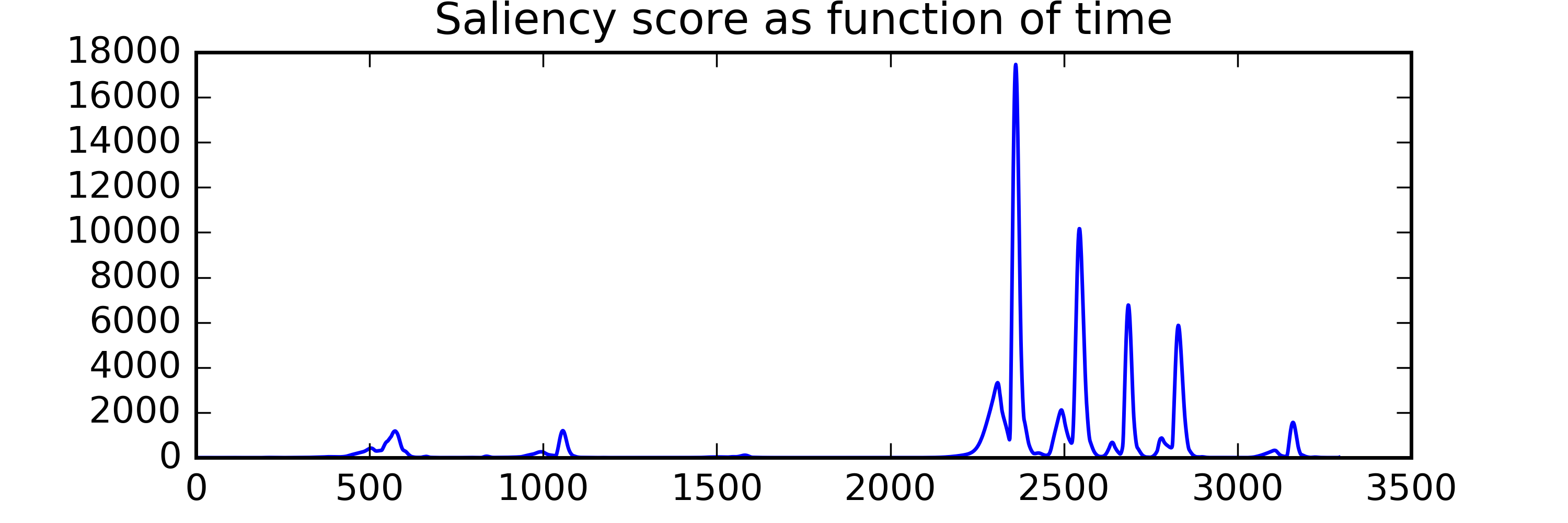
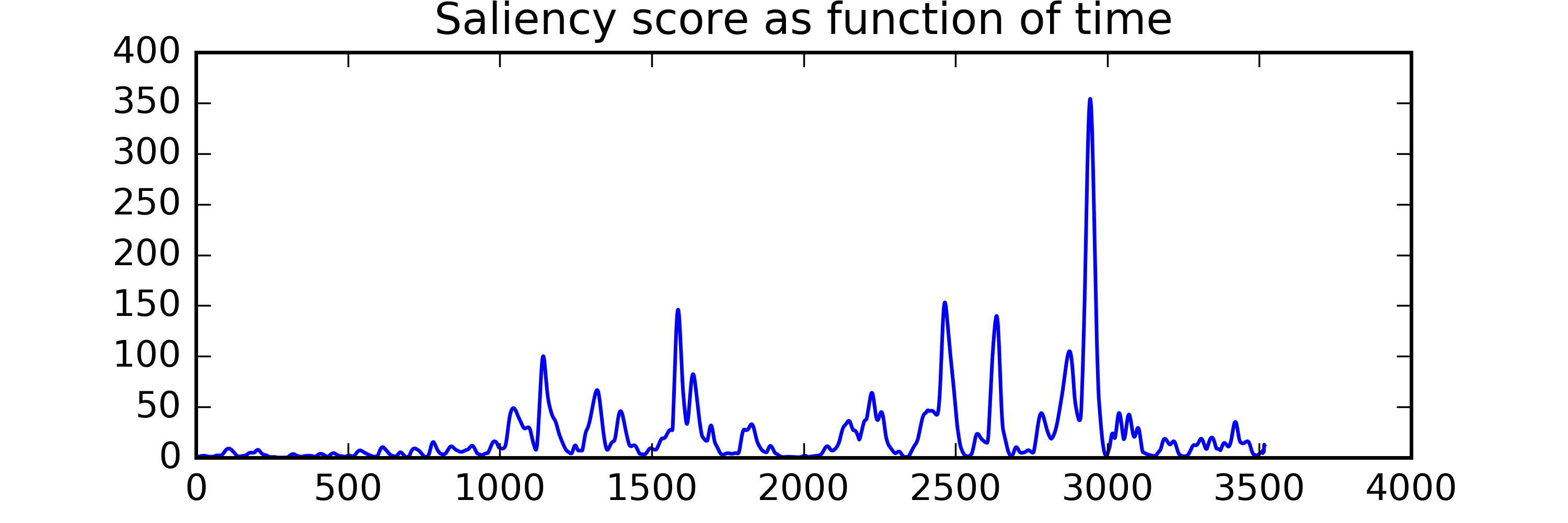
A series of papers from the last decade have demonstrated procedures for calculating auditory salience using 2D kernels with shapes inspired by auditory perception models that are convolved at different scales across audio spectrograms. To obtain a set of low-level salience features that might be useful to help us understand memorability, we’ve implemented a procedure outlined in (Kalinli et. al, 2007) to compute TF salience maps, and have extracted a number of summary statistics from them to use as features in a classifier. These models allow us to extract state-of-the-art features that correspond to how our brains process low level features of the sound, like pitch and timbre. We've included these in our dataset.
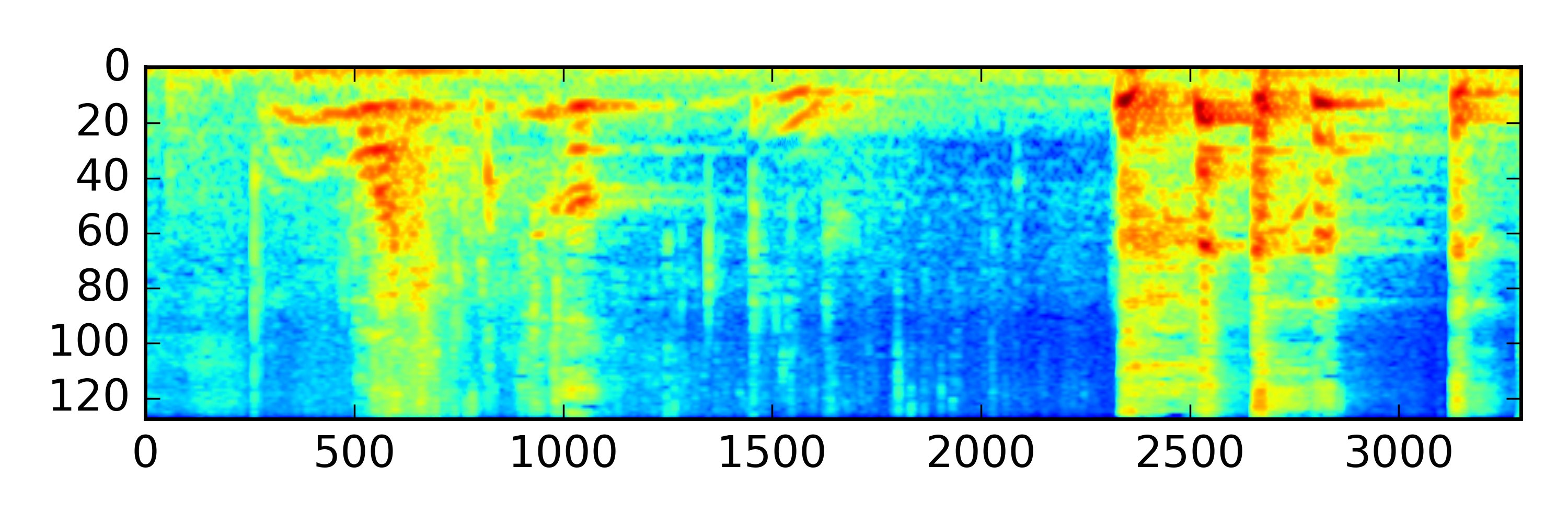
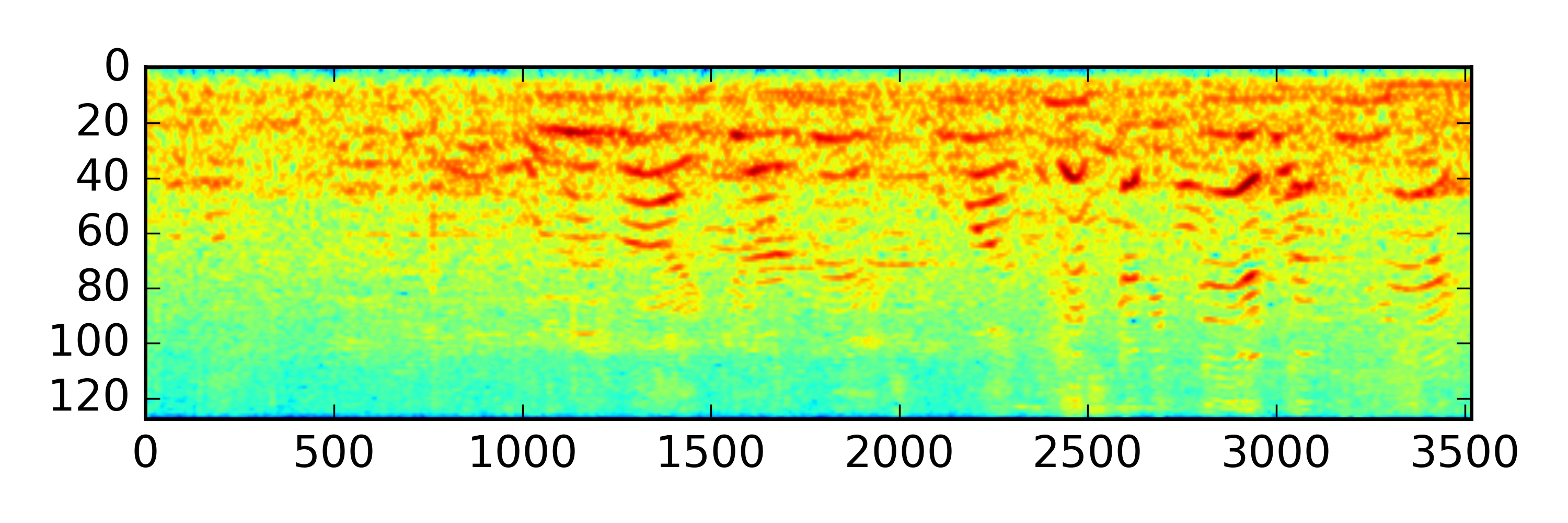
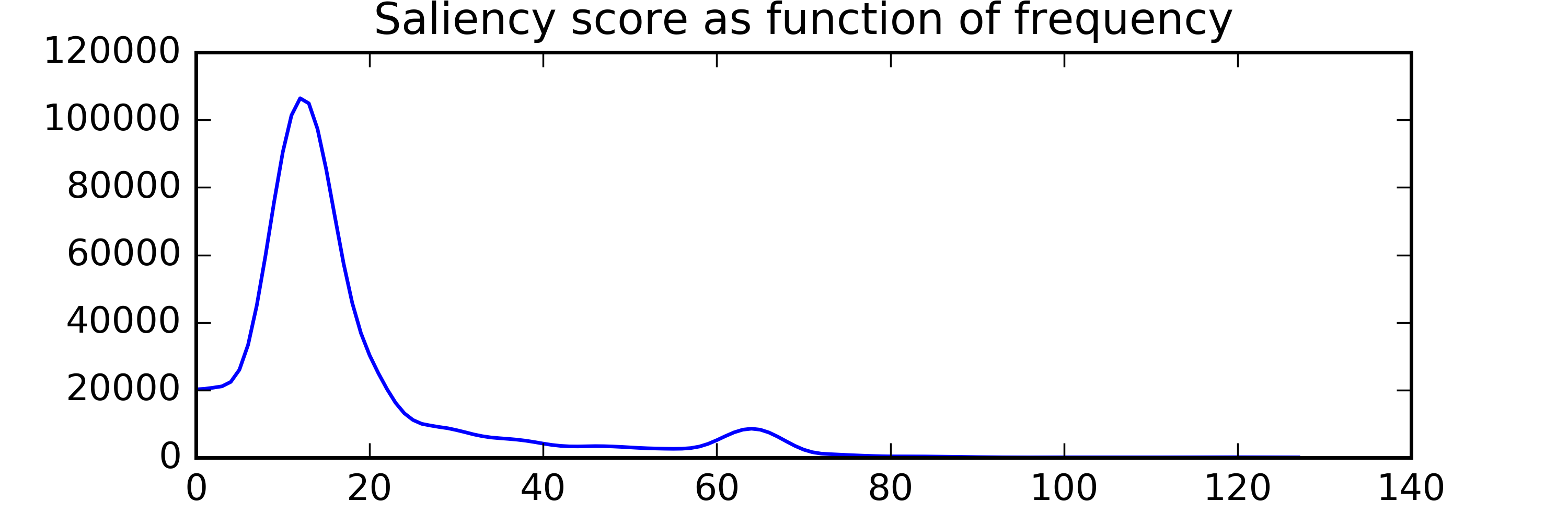
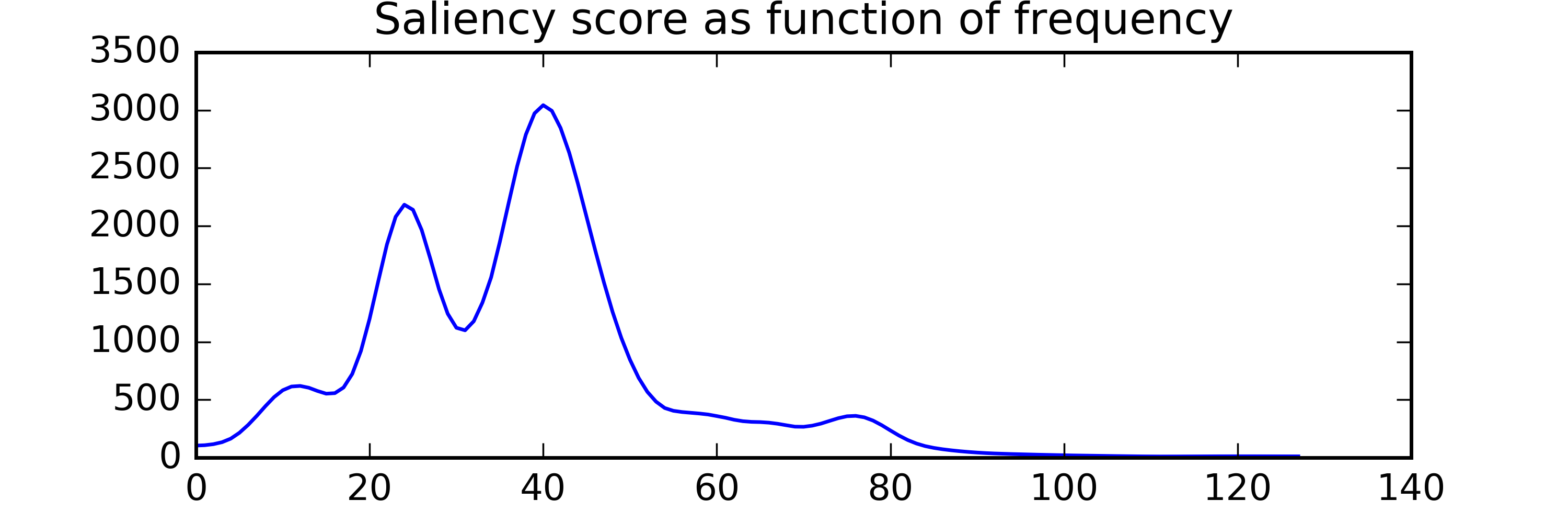
For example, let's compare the temporal salience of two sounds below (click to listen):
| Vomit |
Marketplace |
 |
 |
 |
 |
 |
 |
 |
 |
|
Summary scores:
Total Saliency Score: 1503897.3
Peak Value: 2140.3
Num of peaks in time: 5
Num of peaks in freq: 1
|
Summary scores:
Total Saliency Score: 79324.43
Peak Value: 28.165995
Num of peaks in time: 9
Num of peaks in freq: 2
|
High Level Features
There are many features outside of 'how it sounds' that could affect whether we remember a sound-- is it something you hear every day? Does it bring a vivid image to mind when you hear it? Does it ellicit an emotional response? How easy is it to identify?
To collect higher-level cognitive features associated with sounds, such as the elicited emotion, the level of familiarity, and crowd-sourced labels, we designed an Amazon Turk experiment. An image of the interface is below:

A novel idea that we use in this work is to quantify the consensus between crowd-source labels using off-the-shelf word embedding techniques. In other words, we analyze the spread of the samples in label embedding space to measure how ambiguous a sound is, and whether disagreement amongst individuals plays in memorability. Below is a plot showing how closely related our sounds are based on a ConceptNet embedding of the labels provided by our crowd-sourced workers; the size of the bubble indicates how much concensus there was with for that sound. Click on sounds to hear them and see the provided labels!
Step 2. Measuring Memorability
Now we have a full set of features that could be used to predict a sound's memorability, we need to measure how easily each sound is remembered or forgotten. So, how do we actually know how memorable a sound is? Good question! In 2010, a
paper released by MIT CSAIL used a memory game to determine the features that make faces memorable. We liked the idea, so we used our audio dataset to build our own!
Below is an example of our memory test-- you can try it yourself
here.
This game plays many sounds in a row, some of which repeat. We collected thousands of trials with our test, and we can use this information to quantify how memorable a sound is by looking at the percentage of participants who successfully remember each sound.
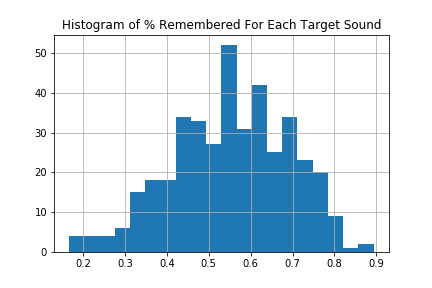
Below we can see that our participants fail to remember the plurality of sounds about 50% of the time, though some sounds are remembered almost 90%, and some fall below 20%!
Here are the five most forgettable and the five most memorable sounds from our dataset. You'll notice all of the forgettable sounds actually sound reasonably similar, and all of them except one come from samples we modified (they don't correspond to natural occuring sounds). The five most memorable, on the other hand, are easily identified, have interesting pitch contours, and are somewhat emotional.
Let’s have a look at how well each of features (low-level and high-level) correlate with our target memorability score using mutual information.
Step 3. A Model of Aural Memorability
Given our small dataset, we first begin by quantizing the memory scores into 3 classes -- highly memorable sounds (greater than 90 percentile of all memory scores), not very memorable sounds (less than 10 percentile of all memory scores), and the remainder of the samples. It is most meaningful from the perspective of our intended future work to find and correctly classify samples that fall at the extremes, instead of obtaining a noisy gradient of memorability.
We are currently working to optimize our classifier model with precisely engineered features.
Step 4. Breaking the Model Down
Low Level Features and Audio Manipulation
* We are working on a model that can predict memorability with high accuracy given our feature set.
* We're going to use this to bootstrap a huge dataset of sounds, and map them to memorability scores based on their low level features and proxy scores for high level ones. Doing this won't allow us to gain any further resolution into the mapping between saliency/high level feature space and memorability, however. What we're interested in instead is developing the time-frequency space. What kinds of transforms can we apply to sounds that make them more or less memorable? We should be able to map out a relatively continuous time-frequency space, even if we're forced to keep saliency space slightly discontinuous to ensure accurate predictions.
* Once we've done this, we should be able to engineer a model that can suggest transformations on audio that make them more or less memorable. With enough audio, it may be possible to build a latent manifold in time-frequency space and explore the manifold, a la conditional GANs.
This takes us to the end of one research trajectory, in which we build devices that manipulate sound files or real-time audio feeds to make them more-or-less memorable.
High Level Features and the Brain
* We're examining models with both low level and high level features for prediction to see how well each works individually. What does their relative success say about the relationships between higher and lower level features? What does it mean for cognition?
* First, we are exploring explicitly how and when each model fails, to see if there are patterns we can exploit for better prediction. Imbuing a model with structure is better than concatenating the features for small datasets.
* After a qualitative examination of our data, we will also be examing causal structures that could explain the data we see. Do we infer a lot about a sound because of it's low level features (i.e. rumbly sounds are made by big machines, and we generally feel a certain way about big machines)? Is it the other way around (a harmless machine makes a rumbly sound like a tiger growling, so we treat it as such)? Do we weigh lower and higher level features differently depending on the type of sound or its ambiguity? We believe that Bayesian Hierarchical Models and Computational Cognitive Science may help us illuminate some of these causal relationships.
Future Directions
*We've created a powerful audio dataset that combines higher and lower level features of sound samples with high quality sounds from a variety of contexts. It also includes conceptually ambiguous sounds.
*We're building models to predict the memorability of sounds based on both high level features that don't require the raw audio, and low level features that only require the raw audio. They work well, and give us flexible options for implementation in the future and insight into the parameters that matter.
*We're working on a model for how the brain processes/stores aural memories using lessons from Computational Cogsci. This should help us in future work on auditory memory, and could serve to compress our model representation. It should also give us insight into when our models that use high- and low- level features will break down.
*We will use this to manipulate the memorability of sounds in our environment with low level features.
*We've laid the groundwork to extend individual sounds into a scene-context, so we can build models of scenes you'll actually hear-- scenes composed of these individual sounds. This will give us the ability to compress audio streams from the top down.