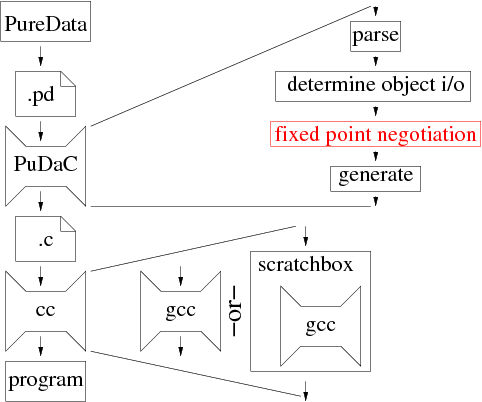
Our PD compiler presents a middle ground between PD and a lower-level language like C, with much of the ease of use of PD and much of the speed of C. By using a highly optimizing C compiler, many of the inefficiencies due to mechanical translation are further eliminated. For example, many objects in PD patches have exactly one incoming connection. A good C compiler, if told to optimize sufficiently, will take these objects and put them inside their callers. Further optimizations would then go and find redundant checks on the data type of the incoming message and discard the second set of checks.
Since we are converting between one format to another of text, we have written the compiler in Perl. Perl excels at parsing text, especially rigidly defined text like PD's save format. After parsing the entire file into a structure in memory, we execute the generators for all the objects that produce the C code for each.
The compiler takes in a plain text PureData patch file and produces C output. This allows us to take advantage of the large amount of work that other people have put into optimizing compilers without having to implement it ourselves.
The PureData Compiler (PuDaC) replaces each object with a uniquely-named subroutine (and possibly some uniquely-named globals). Each ``wire'' connecting objects is replaced with directly calling the connected object.
The compiler runs in two passes (three if you include the additional stage of running gcc). First it parses the input file, loading all the objects into an associative array with a UID for the object as the key. The value of each entry is an another associative array with several predefined entries specifying the object's arguments, the C representation of the objects attached to the inlets and outlets of the object, the C-generating perl code for this object, and a redirection specifying the object has another name (like sel / select). Then it prints a prologue, executes the C-generating perl code for all objects, and prints the main function. This model makes debugging tremendously easier, although it is probably significantly less efficient than is possible.
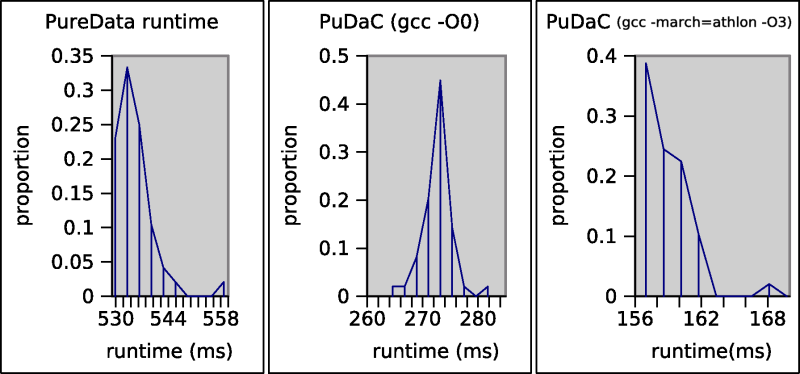
Even so, a simple test patch (which does one million floating point multiplies) shows a significant performance increase over the plain interpreter: on an Athlon (Thunderbird core) running at 1066 MHz, PureData takes an average of 533ms, compared to as little as 158ms for the optimized version of the compiler output, about 30%. (Histograms of trials are below.)
The source to the compiler is available here.